


Connect 👋
Repo 📚
Approach
Introduction
Ever wanted to chat with the content of a PDF, just like you do with ChatGPT? In this blog, I'll show you how I built a system that lets you do exactly that. We'll cover everything from uploading PDFs, processing them to generate vector embeddings, and chatting with the content using a cool interface. This project uses some advanced tech like document processing, vector embeddings, and Docker for easy deployment. Let's dive in!
Project Overview
So, this project is called Chat with PDF - RAG (Retrieval-Augmented Generation). Users can upload PDF files, and the system processes them to generate vector embeddings. These embeddings are stored in a database, and a chat interface uses them to provide context-aware answers to user queries. Everything is containerized with Docker, making it super easy to deploy and scale.
How I Made This Project
Step 1: Setting Up the Environment
First things first, I set up the development environment. Used Node.js, NestJS for the backend, and Next.js for the frontend. We're also using PostgreSQL for data storage, Redis for caching, and BullMQ for handling background tasks.
Step 2: Implementing Document Ingestion
Users can upload PDF files, which get stored in a cloud storage service like AWS S3. The content of these PDFs is extracted and split into smaller chunks.
Step 3: Generating Vector Embeddings
Each content chunk is processed to generate vector embeddings using an API like OpenAI Embeddings. These embeddings are numeric representations that capture the meaning of the text, making it easier to search semantically later.
Step 4: Building the Knowledge Base
The generated embeddings and the corresponding document chunks are stored in a PostgreSQL database. This acts as our knowledge base, making it easy to store and retrieve the embeddings.
Step 5: Implementing the Chat Interface
Users can interact with the PDF content through a chat interface. When a user asks a question, the system converts it into a query embedding and performs a semantic search on the stored document embeddings. The top results are then used to provide context to a large language model (LLM) like GPT-4, which generates a relevant answer.
Step 6: Dockerizing the Application
To ensure the app is easy to deploy and scale, I containerized the backend API and BullMQ worker using Docker. This makes deployment a breeze in any environment that supports Docker.
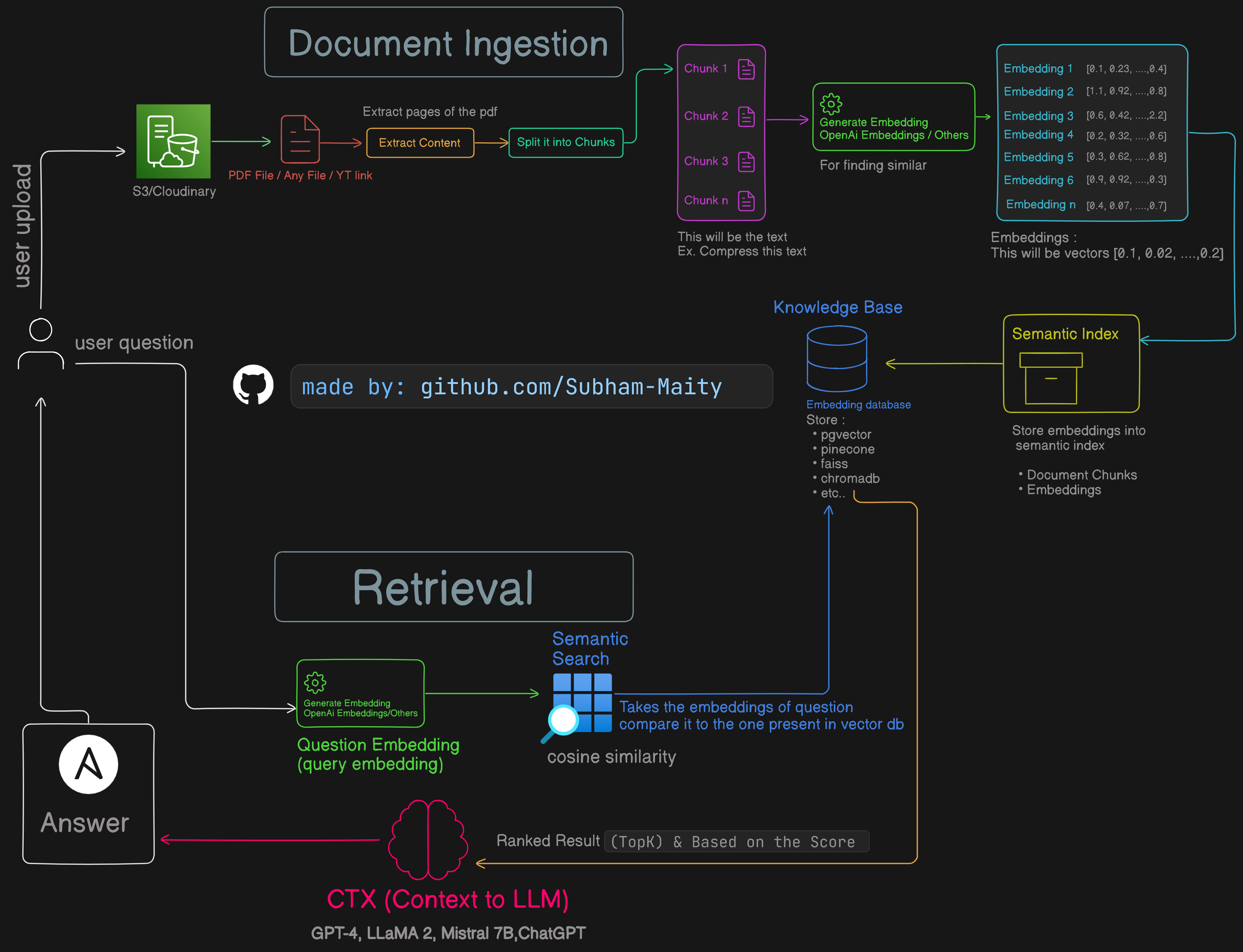
Logic and Architecture
1. Document Ingestion
User Upload: Users upload a PDF file to S3/Cloudinary.
Extract Content: The content of the PDF is extracted.
Split into Chunks: The extracted content is split into manageable chunks.
2. Generate Embeddings
Generate Embeddings: Each chunk is processed to generate vector embeddings using an embedding API (e.g., OpenAI Embeddings).
Embeddings: These are numeric representations of the chunks, capturing the semantic meaning.
3. Knowledge Base
Store Embeddings: The embeddings and document chunks are stored in a database (like PostgreSQL) that acts as the knowledge base.
Embedding Database: Tools like pgvector, pinecone, faiss, or chromadb can be used for storing and indexing these embeddings.
4. Retrieval
User Question: A user asks a question.
Generate Query Embedding: The question is converted into a vector embedding.
Semantic Search: Using the question embedding, a semantic search is performed on the stored document embeddings.
Ranked Result: Results are ranked based on similarity scores (e.g., cosine similarity).
5. Context to LLM (Large Language Model)
CTX: The top-k similar results are used to provide context to the LLM (e.g., GPT-4, LLaMA 2, Mistral 7B, ChatGPT).
Answer: The LLM uses this context to generate and return a relevant answer to the user.
Example (Entire code in my repo)
With frontend and backend
// 1. Document Ingestion
const uploadedPDF = await uploadFileToS3(pdfFile); // Upload PDF to S3
const pdfContent = await extractContentFromPDF(uploadedPDF.path); // Extract content from PDF
const contentChunks = splitContentIntoChunks(pdfContent); // Split content into smaller chunks
// 2. Generate Embeddings
const embeddingModel = new OpenAIEmbeddings(); // Use OpenAI Embeddings (or any other embedding model)
const embeddings = await Promise.all(contentChunks.map(chunk => embeddingModel.embed(chunk))); // Generate embeddings for each chunk
// 3. Knowledge Base
const vectorStore = new PineconeVectorStore(); // Use Pinecone as the vector store (or any other database/index)
await vectorStore.addDocuments(contentChunks, embeddings); // Store document chunks and embeddings in the vector store
// 4. Retrieval
const userQuestion = "What is the main topic of the PDF?"; // User asks a question
const queryEmbedding = await embeddingModel.embed(userQuestion); // Generate embedding for the user's question
const similarChunks = await vectorStore.search(queryEmbedding, topK=5); // Retrieve top-k similar document chunks
// 5. Context to LLM (Large Language Model)
const llm = new GPT4LLM(); // Use GPT-4 as the LLM (or any other LLM model)
const answer = await llm.generate(similarChunks.map(chunk => chunk.content).join("\n")); // Provide retrieved chunks as context to the LLM to generate an answer
console.log(answer); // Print the generated answer
Conclusion
Building this project was an amazing journey, combining several advanced technologies to create a seamless user experience. From document ingestion and embedding generation to creating a chat interface backed by powerful language models, each step was crucial in making the system robust and user-friendly. I hope this post inspires you to dive into similar projects and explore the vast possibilities of combining document processing and AI.